Large language models are powerful, but generating high-quality answers can be both slow and compute-intensive. Streaminator explores a new way to make this process faster and smarter by combining two ideas:
- Speculative Decoding – using a lightweight “draft” model to propose multiple tokens at once, speeding up the normally sequential generation process.
- Multi-Answer Inference – sampling multiple solutions per prompt and selecting the best one, a technique that greatly improves performance on reasoning tasks.
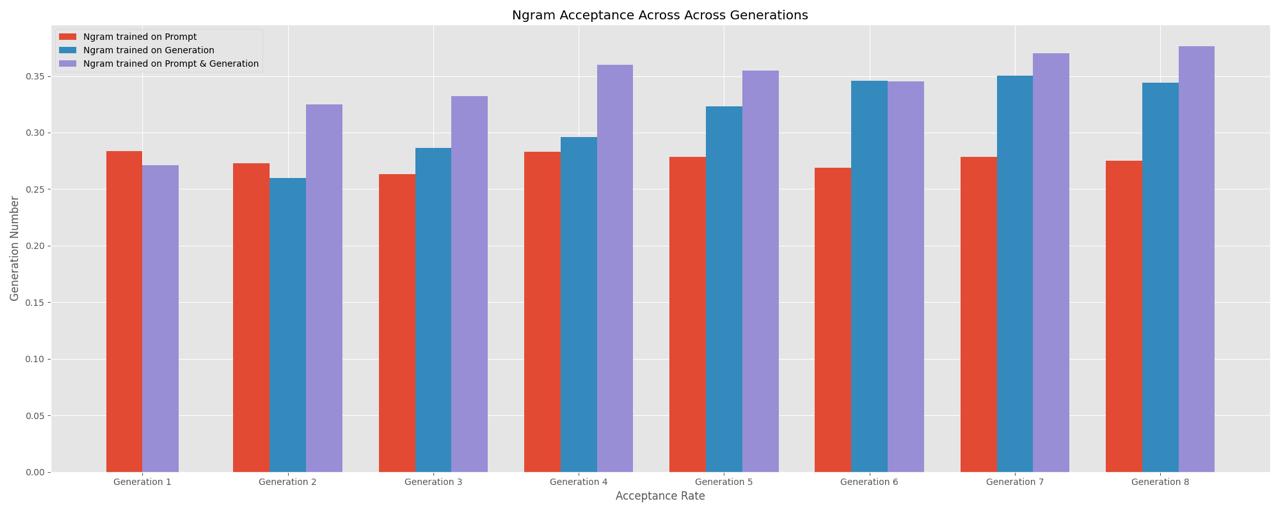
Our key insight: when generating multiple answers for the same prompt, the speculative model can learn from earlier answers to improve its next proposals. Instead of relying on one general-purpose speculator, Streaminator trains a small, prompt-specific model on-the-fly, conditioning it on previous outputs.
The system includes performance optimizations like KV caching and continuous batching, enabling smooth, high-throughput generation on GPUs. In experiments on the GSM8K math reasoning dataset, this approach increased speculative token acceptance rates by 10 percentage points after just three generations—showing that even a simple n-gram speculator can meaningfully guide the decoding process.
Find a more detailed explanation and the full implementation on GitHub.